הסבר על דוח P1
מעקומות סיבוב לעידוש חלש: בדיקת תגובת הכבידה הממוצעת של EFT
עיינו בדוח ההערכה המקורי:
1. ChatGPT: https://chatgpt.com/share/6a00cd62-6e34-83eb-b165-6ec09e3519cc
2. Gemini: https://gemini.google.com/share/773ec96d75a0
3. Grok: https://grok.com/share/bGVnYWN5LWNvcHk_c0b4fa65-0e86-4adb-9b58-5617d616dc04
4. Qwen: https://chat.qwen.ai/s/22ab9336-671f-420a-a7fa-43e24774bb2a?fev=0.2.46
5. DeepSeek: https://chat.deepseek.com/share/tj6k7hb5owtoldg2bm
הערת קריאה |
זוהי גרסת הסבר, לא דוח אקדמי נפרד. היא מבוססת על דוח P1 המקורי, שומרת את האיורים והטבלאות המרכזיים, ומוסיפה הסברים בשפה פשוטה למשמעות כל שלב מרכזי. |
המדריך הזה מסביר רק מה P1 מסיק תחת מערכי הנתונים, פנקס הפרמטרים והפרוטוקול הסטטיסטי המוגדרים שלו: במבחן המשותף של עקומות סיבוב של גלקסיות (RC) ועידוש חלש גלקסיה–גלקסיה (GGL), מודל תגובת הכבידה הממוצעת של EFT עולה בבירור על קו הבסיס המינימלי DM_RAZOR שנבדק כאן. |
מדריך זה אינו מפרש את P1 כטענה ש״החומר האפל הופרך״. P1 הוא רק הצעד הראשון בניסויי סדרת P. הוא בוחן שכבה נצפית אחת של EFT—״רצפת הכבידה הממוצעת״—ולא את מלוא התוכן של מסגרת EFT השלמה. |
0 | הבנת P1 בחמש דקות: מה עושה הבדיקה הזאת?
אפשר לחשוב על P1 כמבחן עקביות בין ערוצי מדידה. הוא אינו שואל רק אם מודל יכול להתאים למערך נתונים אחד. במקום זאת, הוא מניח שני סוגים שונים מאוד של קריאות כבידה על אותו שולחן ביקורת: עקומות סיבוב (RC) קוראות את הדינמיקה בתוך דיסקות של גלקסיות, ואילו עידוש חלש גלקסיה–גלקסיה (GGL) קורא את תגובת הכבידה המוטלת בקני מידה גדולים יותר.
- RC דומה למד־מהירות: הוא אומר לנו באיזו מהירות גז וכוכבים מסתובבים ברדיוסים שונים בדיסקת גלקסיה.
- GGL דומה למאזניים: באמצעות מדידת האופן שבו גלקסיות קדמיות מכופפות מעט את האור מגלקסיות רקע, הוא מסיק את התפלגות הכבידה/המסה הממוצעת סביב גלקסיות בקני מידה גדולים יותר.
- השאלה המרכזית של P1 היא זו: האם אותו מודל יכול ללמוד דפוס תחילה מ־RC, להעביר את הדפוס הזה ל־GGL, ועדיין להישאר הגיוני?
P1 במשפט אחד |
P1 מעלה את הרף מ״האם זה מתאים היטב לערוץ מדידה אחד?״ אל ״האם זה נסגר בין ערוצים?״ סביר יותר שמודל לכד מבנה כבידתי המשותף ל־RC ול־GGL רק אם הוא מתפקד היטב תחת המיפוי הנכון והאות קורס לאחר ערבוב המיפוי. |
טבלה 0 | המספרים המרכזיים של P1 וכיצד לקרוא אותם
משמעות בשפה פשוטה | קריאה ב־P1 / P1A | מדד |
הפרש הציון הכולל בין שני מערכי הנתונים; גדול יותר פירושו הסבר כולל טוב יותר. | בהשוואה שבגוף הטקסט, EFT גבוהה מ־DM_RAZOR ב־1155–1337 | התאמה משותפת ΔlogL_total |
היכולת לחזות GGL לאחר הסקה מ־RC בלבד; גדול יותר פירושו עקביות עצמית חזקה יותר בין ערוצי מדידה. | בהשוואה שבגוף הטקסט, EFT היא 172–281, בעוד DM_RAZOR הוא 127 | חוזק סגירה ΔlogL_closure |
אם ההתאמה הנכונה נשברת, היתרון אמור להיעלם; ככל שהקריסה חדה יותר, כך היא שוללת טוב יותר אות מדומה. | לאחר ערבוב RC-bin→GGL-bin, אות הסגירה של EFT יורד ל־6–23 | ערבוב בקרה שלילית |
P1A אינו בוחן רק את קו הבסיס המינימלי DM_RAZOR. הוא מציב כמה ענפי שיפור DM בממד נמוך וניתנים לביקורת בתוך אותו פרוטוקול סגירה. | DM 7+1 + DM_STD, כאשר EFT_BIN נשמרת כהשוואה | מבחן מאמץ מרובה־DM של P1A |
1 | למה לבצע P1? היכן הקוסמולוגיה בקנה מידה גלקטי תקועה?
בעיות בקנה מידה גלקטי נותרו קשות משום ש״דרישת הכבידה/המסה הנוספת״ אינה רק תופעה של עקומות סיבוב. תצפיות רבות מראות קשר הדוק בין החומר הבריוני הנראה בגלקסיות לבין קריאות הדינמיקה/העידוש בפועל. במסלול של חומר אפל, פירוש הדבר שהילות אפלות, משוב בריוני, היסטוריית היווצרות גלקסיות ושיטתיות תצפיתית חייבים להיות מתואמים בדיוק רב. במסלולי כבידה שאינם חומר אפל, פירוש הדבר שמודל אינו יכול רק להיראות טוב ב־RC; עליו לשרוד גם עידוש חלש, יחסי סקיילינג של אוכלוסיות ובקרות שליליות.
זו המוטיבציה של P1. הוא אינו מתחיל מ״החומר האפל שגוי״ או מ״EFT חייבת להיות נכונה״. הוא מכניס לביקורת טענה אחת הניתנת לבדיקה: האם תגובת הכבידה הממוצעת של EFT יכולה להשאיר אות בר־שחזור ובר־העברה בסגירה בין ערוצי המדידה RC→GGL?
הקשר ספרותי חיצוני: למה חלון RC+GGL חשוב |
יחס התאוצה הרדיאלית (RAR) שהוצע ב־2016 על ידי McGaugh, Lelli ו־Schombert מראה מתאם הדוק ובעל פיזור נמוך בין התאוצה הנצפית הנעקבת על ידי עקומות סיבוב לבין התאוצה החזויה מחומר בריוני. הדבר הופך את ״צימוד בריון–תגובת כבידה״ לבלתי נמנע עבור תיאוריה בקנה מידה גלקטי. |
Brouwer ואחרים (2021) השתמשו בעידוש חלש KiDS-1000 כדי להרחיב את RAR לתאוצות נמוכות יותר ולרדיוסים גדולים יותר, תוך השוואת MOND, כבידה מתהווה של Verlinde ומודלי LambdaCDM. הם גם ציינו שהבדלים בין גלקסיות מוקדמות ומאוחרות, הילות גז והקשר גלקסיה–הילה נותרו סוגיות הסבר מרכזיות. |
Mistele ואחרים (2024) השתמשו בהמשך בעידוש חלש כדי להסיק עקומות מהירות מעגלית עבור גלקסיות מבודדות, ודיווחו שאין ירידה ברורה עד כמה מאות kpc ואף בערך עד 1 Mpc, בהתאמה ל־BTFR. הדבר מראה שעידוש חלש הופך לקריאה חיצונית חשובה לבדיקת תגובת כבידה בקנה מידה גלקטי. |
לכן ערכו של P1 אינו בכך שהוא ״הראשון שדן ב־RC וב־GGL יחד״. ערכו הוא בכך שהוא מציב אותם בתוך פרוטוקול ניתן לביקורת, הבנוי ממיפוי קבוע, פנקס פרמטרים, סגירת RC בלבד→GGL, בקרות שליליות באמצעות ערבוב, ומבחני מאמץ מרובי־DM של P1A.
2 | מה פירוש EFT ב־P1? זו אינה Effective Field Theory
כאן EFT פירושה תורת סיב האנרגיה (Energy Filament Theory, EFT), ולא Effective Field Theory הנפוצה בפיזיקה. בדוח הטכני של P1 נעשה שימוש מרוסן ב־EFT: היא אינה נכנסת להשוואה כתיאוריה סופית שלמה, אלא נדחסת תחילה לפרמטריזציה נצפית, מוכנה להתאמה וניתנת להפרכה של ״תגובת כבידה ממוצעת״.
בשפה פשוטה, P1 אינו מתחיל בדיון בכל מקור מיקרוסקופי של כבידה נוספת, ואינו מנסה להוכיח בבת אחת את כל מסגרת EFT. הוא שואל שאלה צרה וקשה יותר: אם קיימת תגובת כבידה ממוצעת כלשהי בקני מידה גלקטיים, האם היא יכולה תחילה להסביר את RC ואז לעבור לחיזוי GGL?
איזה חלק של EFT נבדק ב־P1? |
P1 מכוון אל ״רצפת הכבידה הממוצעת״: תרומה ממוצעת יציבה סטטיסטית שיכולה לעבור בין מדגמים. |
P1 עדיין אינו מטפל ב״רצפה הסטוכסטית/רצפת הרעש״: איברים אקראיים, הבדלים פרטניים או פיזור נוסף שתהליכי תנודה מיקרוסקופיים יותר עשויים להכניס. |
P1 גם אינו מטפל במנגנון המיקרוסקופי השלם, בשכיחות, במשך החיים או באילוצים קוסמולוגיים גלובליים. זהו הצעד הראשון בניסויי סדרת P, לא פסק דין סופי. |
3 | תוכנית סדרת P1: למה להתחיל מ״הרצפה הממוצעת״?
אפשר להבין את סדרת P כתוכנית השליפה התצפיתית של EFT. היא אינה פורסת את כל הטענות בבת אחת; במקום זאת, היא מבודדת את החלק שניתן לבדיקה בקלות יחסית באמצעות נתונים ציבוריים. האסטרטגיה של P1 היא לבדוק תחילה את האיבר הממוצע: אם תגובת הכבידה הממוצעת אינה מסוגלת אפילו להיסגר מ־RC אל GGL, אז דיון באיברי רעש מורכבים יותר או במנגנונים מיקרוסקופיים חסר נקודת כניסה ראויה.
טבלה 1 | המיקום השכבתי של סדרת P
תפקיד ב־P1 | שאלה שנשאלת | שכבה |
השאלה הראשית של הדוח הנוכחי | האם תגובת כבידה ממוצעת יכולה להיסגר ב־RC→GGL? | P1 |
נספח B: מבחן מאמץ DM 7+1 + DM_STD | אם צד DM מחוזק, האם המסקנה נותרת יציבה? | P1A |
כיוון לעבודה עתידית | האם ניתן להרחיב את הפרוטוקול ליותר נתונים, יותר ערוצי מדידה ושיטתיות מורכבת יותר? | עבודה עתידית בסדרת P |
מחוץ להיקף המסקנות של P1 | איך האיבר הממוצע, איבר הרעש והמנגנון המיקרוסקופי מתחברים? | שאלות ברמה עמוקה יותר |
4 | מהם הנתונים? מה RC ו־GGL אומרים לנו?
4.1 עקומות סיבוב (RC): ״מד המהירות״ בתוך דיסקות גלקטיות
עקומות סיבוב מתעדות כמה מהר גז וכוכבים מקיפים את מרכז הגלקסיה ברדיוסים שונים. ככל שהסיבוב מהיר יותר, כך הכוח הצנטריפטלי הנדרש באותו רדיוס גדול יותר—ולכן גם הכבידה האפקטיבית חזקה יותר. P1 משתמש במסד הנתונים SPARC, עם עיבוד מקדים הכולל 104 גלקסיות ו־2,295 נקודות נתוני מהירות, המחולקות ל־20 תאי RC.
4.2 עידוש חלש (GGL): ״מאזני כבידה״ בקנה מידה גדול יותר
עידוש חלש גלקסיה–גלקסיה מודד כיצד גלקסיות קדמיות מכופפות מעט את האור מגלקסיות רקע. הוא תואם לתגובת כבידה מוטלת ברדיוסים גדולים יותר, בקנה מידה של הילה, ואינו תלוי בפרטי דינמיקת הגז בתוך גלקסיה. P1 משתמש בנתוני GGL הציבוריים מ־KiDS-1000 / Brouwer et al. (2021): ארבעה תאי מסה כוכבית, 15 נקודות רדיאליות לכל תא, 60 נקודות נתונים בסך הכול, תוך שימוש בקווריאנציה המלאה.
4.3 מיפוי קבוע: למה 20 תאי RC → 4 תאי GGL חשובים
P1 מחבר את 20 תאי RC אל 4 תאי GGL באמצעות כלל קבוע: כל תא GGL מתאים ל־5 תאי RC, המשולבים בממוצע משוקלל לפי מספר הגלקסיות. המיפוי הזה נשמר ללא שינוי עבור כל המודלים ומשמש אילוץ קשיח לבדיקת סגירה ולהשוואה הוגנת.
למה לא לכוון את המיפוי לאחר מעשה? |
אילו היה אפשר לבחור בדיעבד ״אילו תאי RC מתאימים לאילו תאי GGL״, מודל היה עלול לייצר סגירה באמצעות סידור מחדש של ההתאמה. P1 נועל מראש את המיפוי 20→4 ושובר אותו בכוונה באמצעות בקרה שלילית של ערבוב, בדיוק כדי לשפוט אם אות הסגירה באמת תלוי בהתאמה סבירה מבחינה פיזיקלית. |
5 | מודלים ושיטות: מה בדיוק P1 משווה?
5.1 צד EFT: תגובת כבידה ממוצעת בממד נמוך
בצד EFT נעשה שימוש באיבר מהירות נוספת בממד נמוך כדי לתאר תגובת כבידה ממוצעת. צורת האיבר הנוסף נשלטת בידי פונקציית גרעין חסרת ממד f(r/ℓ), כאשר ℓ הוא הסקייל הגלובלי, והמשרעת מוקצית לפי תא RC. גרעינים שונים מייצגים שיפועים התחלתיים שונים, מהירויות מעבר וזנבות ארוכי טווח, ומשמשים למבחני מאמץ של חסינות.
5.2 צד DM: יש לקרוא בנפרד את ההשוואה בגוף הטקסט ואת נספח P1A
בהשוואה שבגוף הטקסט, DM_RAZOR הוא קו בסיס NFW ממוזער וניתן לביקורת: הוא משתמש ביחס c–M קבוע ואינו כולל פיזור בין הילה להילה, כיווץ אדיאבטי, ליבות משוב, אי־כדוריות או איברים סביבתיים. חוזק התכנון הזה הוא דרגות חופש נשלטות ושחזור קל; חולשתו היא שהוא אינו יכול לייצג כל מודל LambdaCDM או כל מודל של הילת חומר אפל.
לכן, בנספח B (P1A), צד DM הופך למערכת של ״מבחני מאמץ סטנדרטיים״. בלי לשנות את המיפוי המשותף או את פרוטוקול הסגירה, P1A מוסיף בהדרגה ענפי שיפור בממד נמוך כגון SCAT, AC, FB, HIER_CMSCAT, CORE1P, פרמטר העידוש m, וקו הבסיס המשולב DM_STD, תוך השארת EFT_BIN כהשוואה. בקצרה, P1A אינו השוואה רק מול קו בסיס DM מינימלי אחד; הוא מודד מערכת של מנגנוני DM נפוצים וניתנים לביקורת באמצעות אותו ״סרגל סגירה״.
מסגור המסקנה המדויק המשמש כאן |
גוף הטקסט: משפחת EFT עולה במידה ניכרת על DM_RAZOR המינימלי בהשוואה הראשית. |
נספח B / P1A: תחת כמה ענפי שיפור DM בממד נמוך וניתנים לביקורת ומבחן המאמץ DM_STD, חלק מההתאמות המשותפות של DM משתפרות, אך חוזק הסגירה אינו מבטל את יתרון EFT_BIN. |
לכן הניסוח הבטוח ביותר הוא: בתוך הנתונים, המיפוי, פנקס הפרמטרים ופרוטוקול הסגירה של P1/P1A, תגובת הכבידה הממוצעת של EFT מראה עקביות חזקה יותר בין נתונים; אין זה שקול לשלילת כל מודלי החומר האפל. |
5.3 בדיקת סגירה: התחביר הניסויי החשוב ביותר של P1
1. לבצע התאמה באמצעות RC בלבד כדי לקבל אוסף דגימות posterior של RC בלבד.
2. לא לכייל מחדש בעזרת GGL; להשתמש ישירות ב־posterior של RC כדי לחזות GGL.
3. להשתמש בקווריאנציה המלאה כדי לחשב את ציון חיזוי GGL תחת המיפוי הנכון, logL_true.
4. לערבל באקראי את ההתאמה RC-bin→GGL-bin כדי לחשב את ציון הבקרה השלילית, logL_perm.
5. לחסר את השניים כדי לקבל את חוזק הסגירה: ΔlogL_closure = <logL_true> − <logL_perm>.
אנלוגיה בשפה פשוטה |
מבחן סגירה דומה למבחן חוזר בחקירה נגדית. המודל לומד תחילה דפוסים בחדר הבחינה של RC, ואז עונה בחדר הבחינה של GGL. אם הוא למד כלל משותף ולא טריק מקומי, עליו לענות היטב גם אחרי מעבר חדרים; אם ההתאמה בין חדרי הבחינה מעורבבת בכוונה, היתרון אמור להיעלם. |
5.4 לפני קריאת הטבלאות הטכניות: ארבע נקודות כניסה
טבלה 5.4 | מסלול קריאה לקבוצת הטבלאות הטכניות הרחבות הבאה
למה זה חשוב | על מה להסתכל | נקודת כניסה |
עונה על השאלה: ״כאשר שני מערכי הנתונים נבחנים יחד, ההסבר הכולל של מי חזק יותר?״ | ציון כולל של התאמה משותפת RC+GGL | טבלה S1a |
עונה על השאלה: ״האם מה שנלמד מ־RC יכול לעבור ל־GGL?״ | חוזק סגירה, ערבוב וסריקות חסינות | טבלה S1b |
מונע מצמצום P1 ל״רק השוואה עם DM_RAZOR מינימלי״. | הגדרות של כמה ענפי שיפור DM ב־P1A | טבלה B0 |
בודק אם יתרון הסגירה נעלם לאחר חיזוק DM. | לוח תוצאות סגירה והתאמה משותפת של P1A | טבלה B1 |
הערת פריסה |
עמודי רוחב מתחילים בעמוד הבא, כדי שניתן יהיה לשמור את הטבלאות הרחבות מן הדוח המקורי בשלמותן בלי למחוק עמודות או לדחוס אותן עד כדי חוסר קריאות. גוף הטקסט כבר נתן קריאה בשפה פשוטה; הטבלאות הטכניות הרוחביות מיועדות לקוראים שצריכים לאמת ערכים וענפי מודלים. |
איור 0.1 | זרימת העבודה של מבחן הסגירה ב־P1 בתרשים אחד
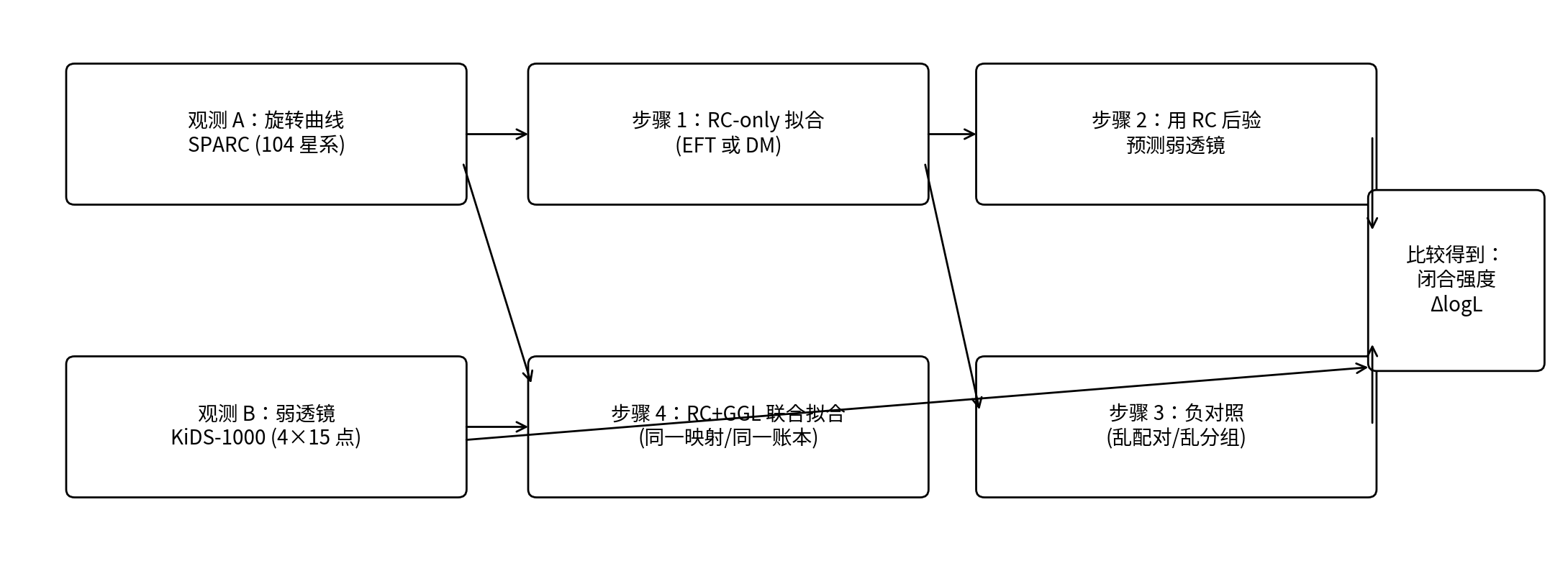
הערה: השרשרת העליונה היא ״מבחן הסגירה״ (התאמת RC בלבד → שימוש ב־posterior של RC לחיזוי GGL); השרשרת התחתונה היא ״התאמה משותפת״ (ניקוד RC+GGL יחד). מימין, המיפוי האמיתי מושווה למיפוי המעורבל כדי לקבל את חוזק הסגירה ΔlogL.
6 | טבלאות טכניות מרכזיות: הטבלאות הראשיות מן הדוח המקורי וטבלאות P1A
טבלה S1a | מדדי ההשוואה הראשיים של התאמה משותפת (RC+GGL, קפדני; נשמר מן הדוח המקורי)
BIC | AICc | ΔlogL_total מול DM | Joint logL_total (הטוב ביותר) | k | גרעין W | מודל (workspace) |
34010.811 | 33895.885 | 0.0 | -16927.763 | 20 | ללא | DM_RAZOR |
31344.155 | 31223.501 | 1337.21 | -15590.552 | 21 | ללא | EFT_BIN |
31500.711 | 31380.057 | 1258.932 | -15668.83 | 21 | אקספוננציאלי | EFT_WEXP |
31708.922 | 31588.268 | 1154.827 | -15772.936 | 21 | יוקאווה | EFT_WYUK |
31429.692 | 31309.038 | 1294.442 | -15633.321 | 21 | זנב_חוק_חזקה | EFT_WPOW |
טבלה S1b | מדדי סגירה וחסינות (קפדני; נשמר מן הדוח המקורי)
טווח ΔlogL בסריקת cov-shrink | טווח ΔlogL בסריקת R_min | טווח ΔlogL בסריקת σ_int | ΔlogL אחרי ערבוב בקרה שלילית | ΔlogL של סגירה (true-perm) | מודל (workspace) |
— | — | — | 22.725 | 126.678 | DM_RAZOR |
1337–1351 | 1243–1289 | 459–1548 | 14.984 | 231.611 | EFT_BIN |
1259–1277 | 1169–1207 | 408–1471 | 6.04 | 171.977 | EFT_WEXP |
1155–1166 | 1065–1099 | 380–1341 | 14.688 | 179.808 | EFT_WYUK |
1294–1308 | 1203–1247 | 457–1500 | 6.672 | 280.513 | EFT_WPOW |
טבלה B0 | הגדרות ענפי השיפור של DM ב־P1A (נשמר מנספח B של הדוח המקורי)
עקרון יישום (ידידותי לביקורת) | מוטיבציה פיזיקלית (ליבה) | פרמטר חדש (≤1) | dm_model | Workspace |
|---|---|---|---|---|
מיפוי משותף קבוע; פנקס פרמטרים קפדני; משמש רק כקו בסיס להשוואה יחסית | קו בסיס מינימלי וניתן לביקורת של הילות LambdaCDM; משמש להשוואה קפדנית עם EFT | — | NFW (c–M קבוע, ללא פיזור) | DM_RAZOR |
≤1 פרמטר חדש; עדיין משתמש במיפוי המשותף; רווח הסגירה הוא קריטריון הקבלה | ליחס c–M יש פיזור; הוא מקורב באמצעות פיזור log-normal בפרמטר אחד | σ_logc | NFW + פיזור c–M (legacy) | DM_RAZOR_SCAT |
≤1 פרמטר חדש; המיפוי אינו משתנה; מדווח על שינויי AICc/BIC ועל רווח הסגירה | נפילת חומר בריוני פנימה עשויה לגרום לכיווץ אדיאבטי של ההילה; היא מקורבת באמצעות חוזק בפרמטר אחד | α_AC | NFW + כיווץ אדיאבטי (legacy) | DM_RAZOR_AC |
≤1 פרמטר חדש; אותו מסגור של סגירה/בקרה שלילית; שיפור RC בלבד אינו המטרה היחידה | משוב עשוי ליצור ליבה פנימית; היא מקורבת באמצעות סקייל ליבה בפרמטר אחד | log r_core | NFW + ליבת משוב (legacy) | DM_RAZOR_FB |
prior מפורש; c_i לטנטי עובר marginalization; נשאר בממד נמוך וניתן לביקורת | c_i∼logN(c(M_i),σ_logc) היררכי סטנדרטי יותר; משפיע על posterior משותף של RC ו־GGL | σ_logc(hier) | פיזור c–M היררכי + prior | DM_HIER_CMSCAT |
מצטט ספרות סטנדרטית; ≤1 פרמטר חדש; קשור למבחן הסגירה | משתמש ב־proxy ליבה בפרמטר אחד עבור האפקט העיקרי של משוב בריוני, תוך הימנעות מפרטי היווצרות כוכבים רב־ממדיים | log r_core | proxy ליבה בפרמטר אחד (בהשראת coreNFW/DC14) | DM_CORE1P |
ה־nuisance מתועד במפורש; אינו מורשה להשפיע בחזרה על RC; התוצאות נשפטות בעיקר לפי חסינות הסגירה | סופג שיטתיות מרכזית בצד העידוש החלש באמצעות פרמטר אפקטיבי, ומפחית את הסיכון להתייחס לשיטתיות כאל פיזיקה | m_shear(GGL) | NFW + nuisance של כיול shear בעידוש | DM_RAZOR_M |
מדווח יחד על פנקס הפרמטרים ועל קריטריוני המידע; הסגירה היא המדד הראשי; משמש כהשוואת ההגנה החזקה ביותר של DM | מביא את שלוש ההתנגדויות הנפוצות ביותר לתוך קו בסיס סטנדרטי אחד שעדיין נותר בממד נמוך | σ_logc + log r_core (+ m_shear) | קו בסיס DM סטנדרטי (HIER_CMSCAT + CORE1P + m) | DM_STD |
טבלה B1 | לוח התוצאות של P1A (גדול יותר טוב יותר; נשמר מנספח B של הדוח המקורי)
ה־logL_total המשותף הטוב ביותר (Δ) | חוזק סגירה ΔlogL_closure (Δ) | ה־logL_RC הטוב ביותר של RC בלבד (Δ) | Δk | ענף מודל (workspace) |
-27347.068 (+0.000) | 122.205 (+0.000) | -15702.654 (+0.000) | 0 | DM_RAZOR |
-23153.311 (+4193.758) | 121.236 (-0.969) | -15702.294 (+0.361) | 1 | DM_RAZOR_SCAT |
-23982.557 (+3364.511) | 121.531 (-0.674) | -15703.689 (-1.035) | 1 | DM_RAZOR_AC |
-27478.531 (-131.463) | 129.454 (+7.249) | -15496.046 (+206.609) | 1 | DM_RAZOR_FB |
-23153.160 (+4193.908) | 121.978 (-0.227) | -15702.644 (+0.010) | 1 | DM_HIER_CMSCAT |
-27336.258 (+10.810) | 122.056 (-0.149) | -15723.158 (-20.504) | 1 | DM_CORE1P |
-27340.451 (+6.617) | 122.205 (+0.000) | -15702.654 (+0.000) | 0 (+m) | DM_RAZOR_M |
-22984.445 (+4362.623) | 105.690 (-16.515) | -15832.203 (-129.549) | 2 (+m) | DM_STD |
-19001.142 (+8345.926) | 204.620 (+82.415) | -14631.537 (+1071.117) | 1 | EFT_BIN |
איך לקרוא את טבלה B1 (לוח התוצאות של P1A) |
• Δk: דרגות חופש חדשות שנוספו (גדול יותר פירושו מודל מורכב יותר; מורכב יותר אינו אומר אוטומטית טוב יותר). • התמקדו בשתי עמודות: חוזק הסגירה ΔlogL_closure(Δ) (גדול יותר פירושו עקביות־העברה עצמית חזקה יותר) ו־Joint best logL_total(Δ) (הציון הכולל של ההתאמה המשותפת). • הערך בסוגריים, (Δ), הוא ההפרש ביחס ל־DM_RAZOR, מה שמקל על השוואה ישירה. |
• השאלה המרכזית שהטבלה שואלת היא האם יתרון הסגירה נעלם לאחר שקו הבסיס של DM ״חוזק באופן סביר״. • טיפ קריאה: DM_STD משפר באופן ניכר את הציון המשותף, אך חוזק הסגירה שלו יורד; EFT_BIN עדיין נשארת גבוהה יותר בחוזק הסגירה. |
במשפט אחד: בתוך מערכת שיפורי DM בממד נמוך וניתנת לביקורת זו, שיפור ההתאמה המשותפת אינו מייצר אוטומטית סגירה חזקה יותר; סגירה, כלומר יכולת העברה, נותרת הקריטריון המרכזי. |
7 | כיצד יש לקרוא את התוצאות העיקריות?
7.1 התאמה משותפת: כשמסתכלים על שני מערכי הנתונים, ציון ההשוואה הראשית של EFT גבוה יותר
טבלה S1a ואיור S4 מראים כי תחת אותם נתונים, אותו מיפוי משותף ובערך אותו סקייל פרמטרים, למשפחת EFT יש ΔlogL_total משותף של 1155–1337 ביחס ל־DM_RAZOR. קורא כללי יכול להבין זאת כך: תחת אותו כלל ניקוד המיושם על RC ו־GGL יחד, מודלי ההשוואה הראשית של EFT מקבלים ציון כולל גבוה יותר.
7.2 מבחן סגירה: מה ש־P1 מבקש להדגיש יותר מכול הוא ״יכולת העברה״
חוזק סגירה גבוה פירושו שפרמטרים שהוסקו מ־RC בלבד יכולים לחזות GGL טוב יותר בלי להביט שוב ב־GGL. בדוח P1, ערך ΔlogL_closure של EFT הוא 172–281, בעוד DM_RAZOR הוא 127. תוצאה זו חשובה יותר מן האמירה ש״כל מודל מתאים היטב לנתונים שלו״, משום שהיא מגבילה את חופש המודל במערך הנתונים השני.
7.3 בקרה שלילית: למה ״קריסת אות״ היא דבר טוב?
לאחר ש־P1 מערבל באקראי את התאמת הקבוצות RC-bin→GGL-bin, אות הסגירה של EFT יורד לטווח 6–23. לקורא כללי, שלב זה דומה לבדיקת אנטי־רמאות: אם יתרון הסגירה היה נוצר רק מקוד, יחידות, טיפול בקווריאנציה או מקריות התאמה, ייתכן שהיתרון היה נשאר גם תחת התאמה מעורבלת. במקום זאת, היתרון בפועל קורס, ומראה שהוא תלוי במיפוי הנכון.
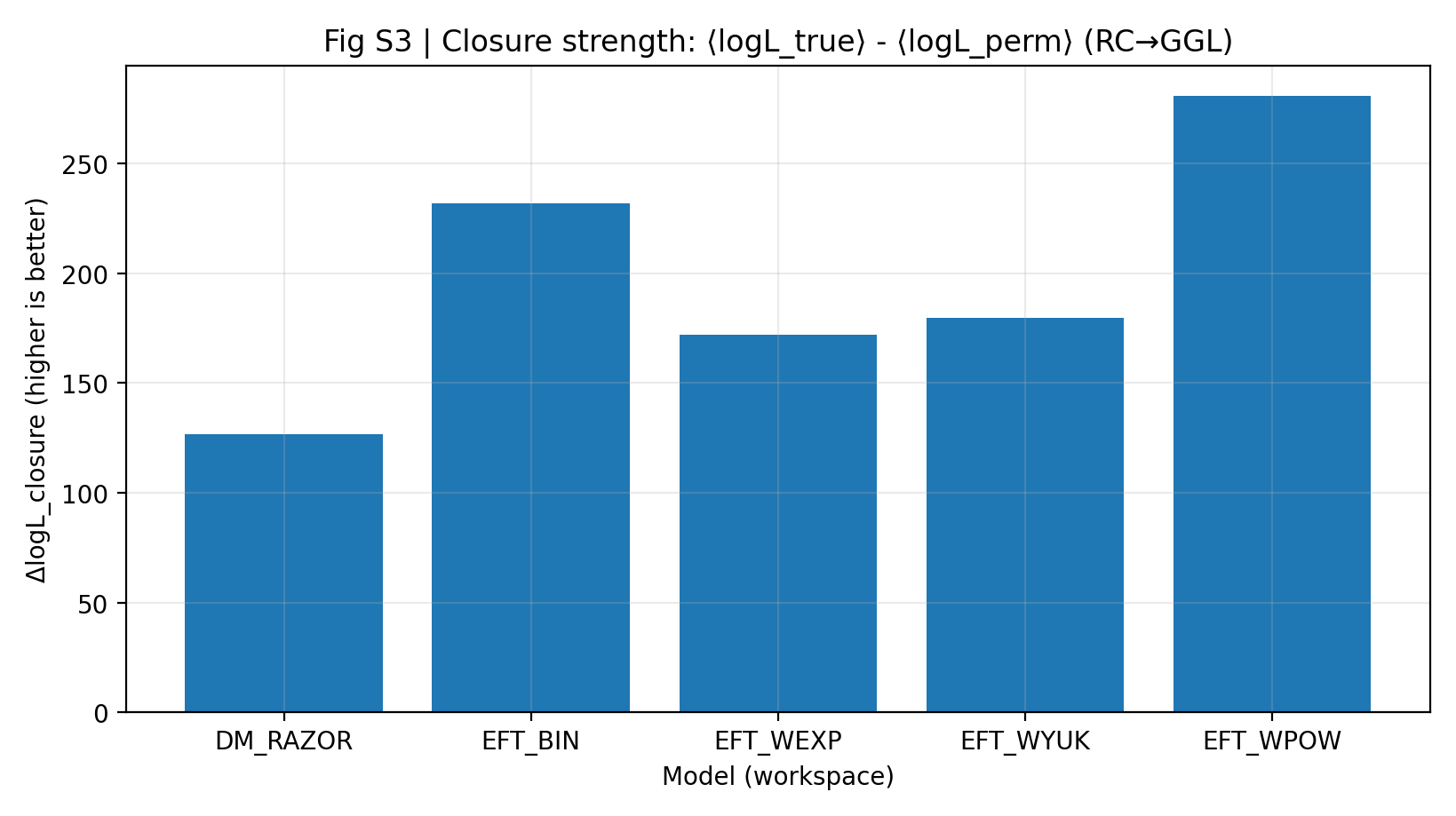
איור S3 | חוזק הסגירה (גדול יותר טוב יותר): יתרון ממוצע בלוג־סבירות עבור חיזוי RC בלבד → GGL.
איך לקרוא את האיור הזה |
האיור הזה הוא הליבה של P1. ככל שהעמודה גבוהה יותר, כך המידע שנלמד מ־RC עובר טוב יותר ל־GGL. |
משפחת EFT גבוהה יותר בסך הכול מ־DM_RAZOR, מה שמצביע על סגירה חזקה יותר של EFT בין ערוצי מדידה בניסוי ״לומדים תחילה RC, ואז חוזים GGL״. |
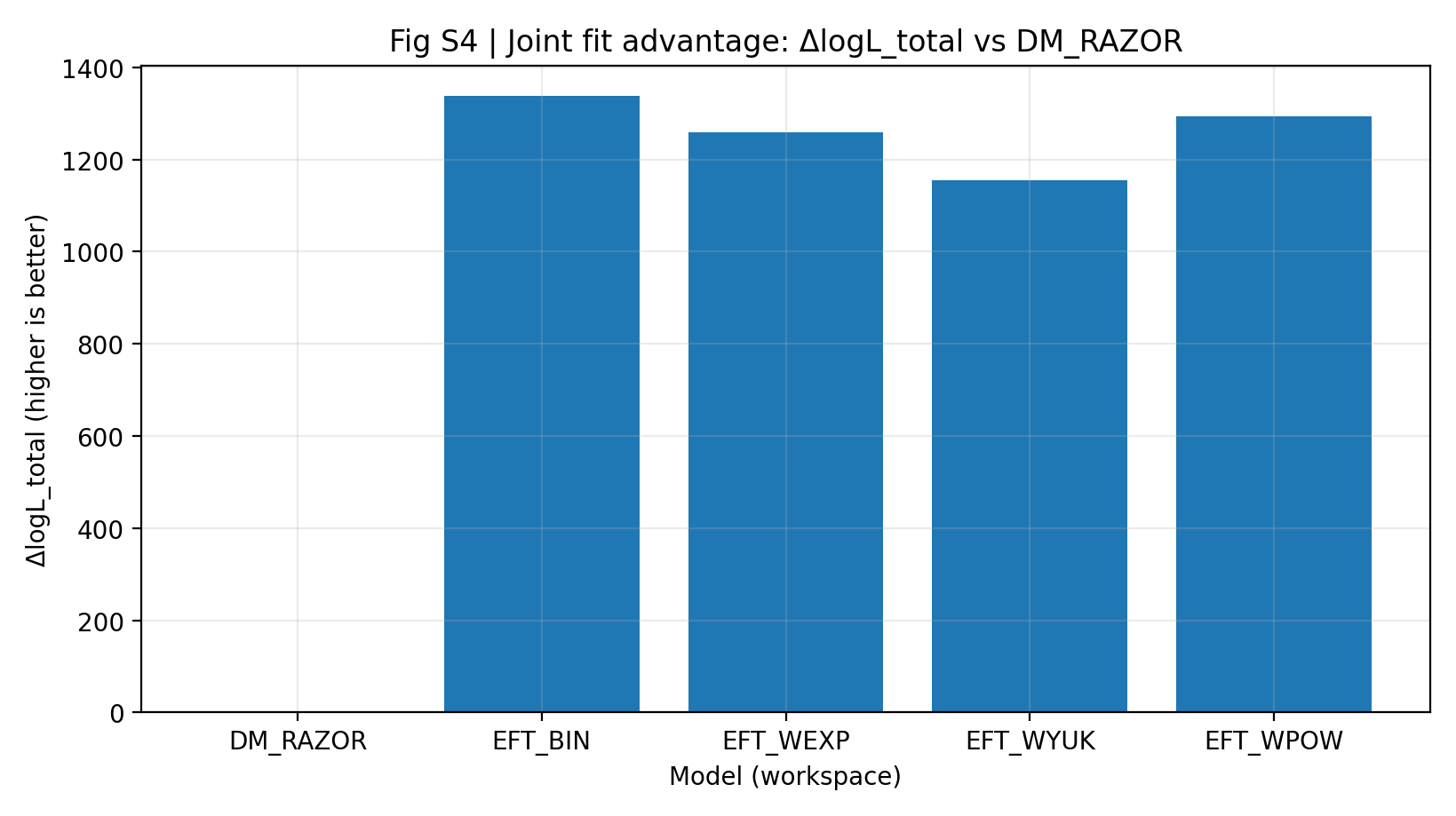
איור S4 | יתרון ההתאמה המשותפת (גדול יותר טוב יותר): logL_total הטוב ביותר של RC+GGL ביחס ל־DM_RAZOR.
איך לקרוא את האיור הזה |
האיור הזה מציג את הציון הכולל לאחר שילוב RC ו־GGL. |
כל מודלי EFT נמצאים הרבה מעל 0, מה שמצביע על כך שיתרון EFT בהשוואה הראשית אינו אפקט מקומי של נקודה אחת אלא דפוס כולל בניתוח המשותף. |
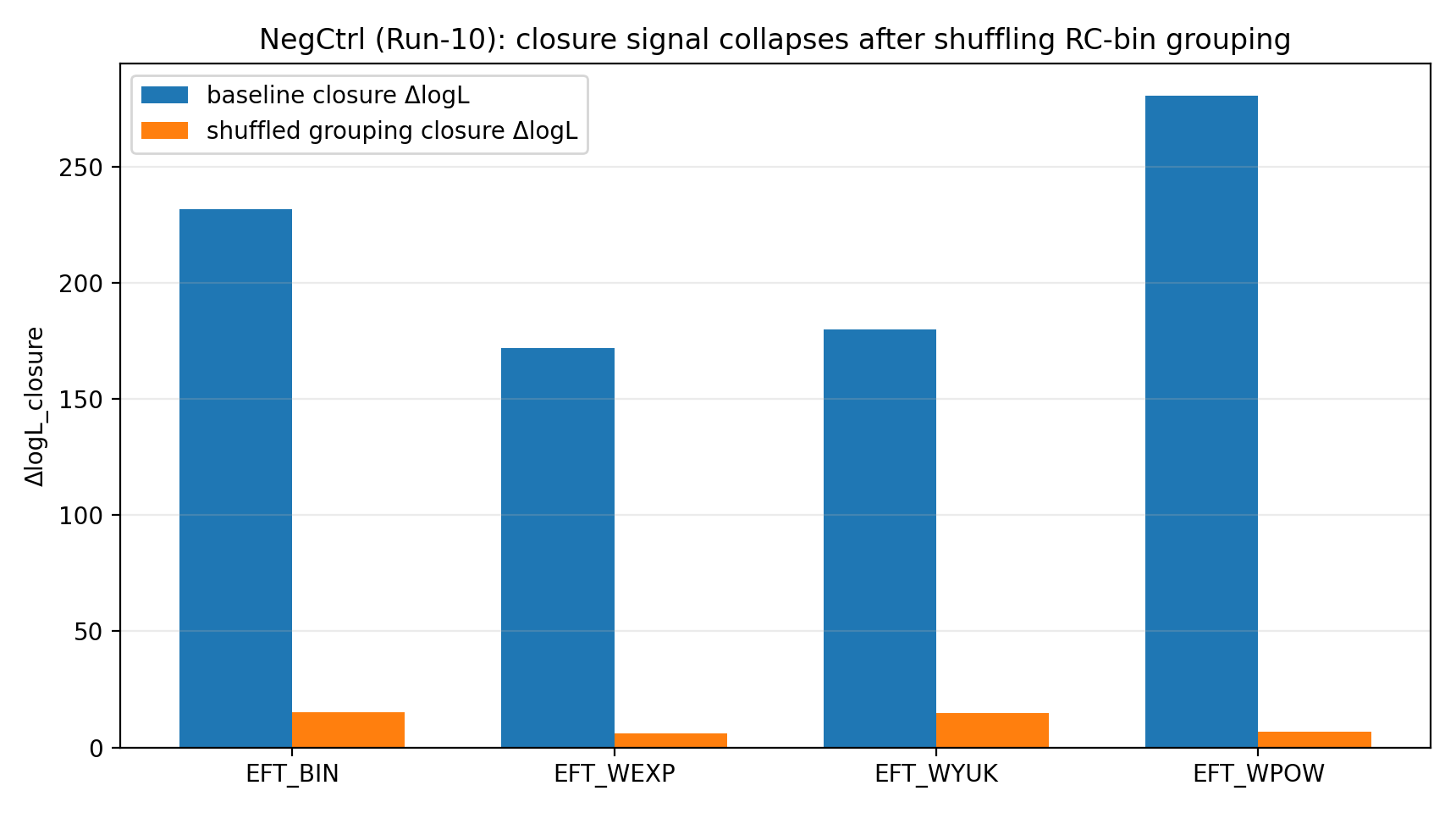
איור R1 | בקרה שלילית: אות הסגירה יורד בחדות לאחר ערבוב הקיבוץ.
איך לקרוא את האיור הזה |
האיור הזה מראה שכאשר יחסי התאים הנכונים בין RC↔GGL משובשים, אות הסגירה יורד בחדות. |
זה גורם לתוצאת P1 להיראות יותר כעקביות אמיתית במיפוי בין נתונים, ולא כצירוף מקרים מספרי שניתן לקבל תחת מיפויים שרירותיים. |
8 | חסינות ובקרות: כיצד P1 נמנע מלהיות ״רק התאמה שנראית טוב״?
האתגר הקל ביותר מול דוח טכני הוא לשאול אם היתרון מגיע מהגדרת רעש אחת, מחיתוך נתונים אחד של אזור מרכזי, מטיפול אחד בקווריאנציה או מהתאמת יתר. P1 מתמודד עם זאת באמצעות כמה מבחני מאמץ.
טבלה 2 | כיצד לקרוא את מבחני החסינות והבקרות השליליות של P1
כיצד לקרוא אותה | החשש שהיא מנסה לשלול | בדיקה |
לאחר הרפיית שגיאות RC, דירוג EFT וסקייל היתרון נשארים יציבים. | אם RC מכיל פיזור לא ידוע נוסף, האם המסקנה נשארת יציבה? | סריקת σ_int |
לאחר קיטום האזורים המרכזיים, EFT עדיין שומרת על יתרון חיובי. | אם אין אמון מלא באזורים המרכזיים של הגלקסיות, האם המסקנה נשארת יציבה? | סריקת R_min |
לאחר כיווץ הקווריאנציה לכיוון האלכסון, היתרון אינו רגיש. | אם אומדן הקווריאנציה של GGL אינו ודאי, האם המסקנה נשארת יציבה? | סריקת cov-shrink |
EFT_BIN המלא נתמך על ידי קריטריוני המידע. | האם EFT נשענת על מורכבות מיותרת כדי לכפות התאמה? | סולם אבלציה |
לאחר הוצאה של תא GGL, המודל עדיין מראה ביצועי הכללה חזקים. | האם המודל מסביר רק נתונים שכבר ראה? | חיזוי LOO על נתונים שהוחזקו בחוץ |
הסגירה יורדת לאחר ערבוב הקיבוץ, ותומכת בתלות במיפוי. | האם הסגירה מגיעה מן המיפוי האמיתי? | ערבוב תאי RC |
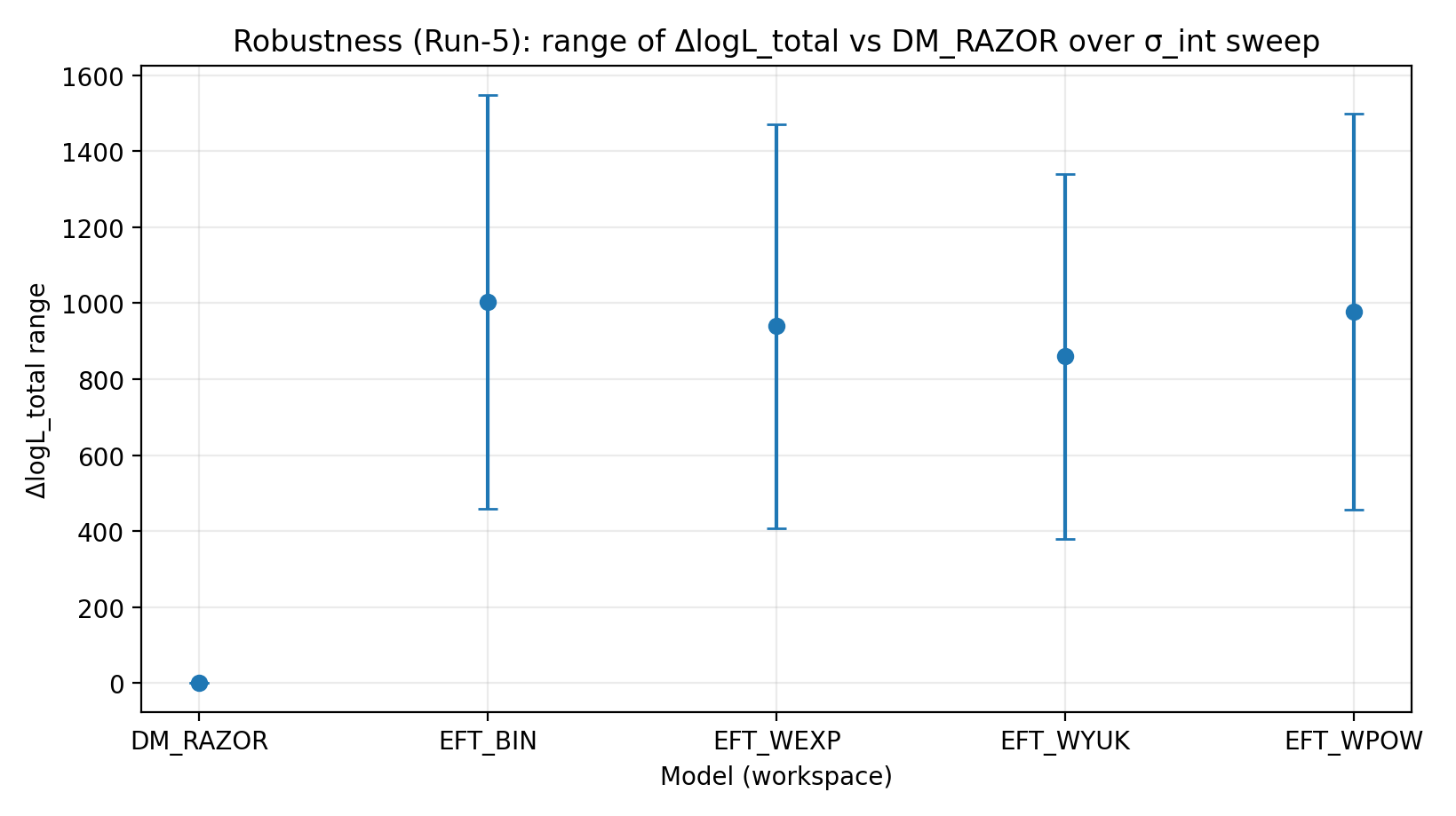
איור R2 | טווח ΔlogL_total תחת סריקת σ_int (גדול יותר טוב יותר).
איך לקרוא את האיור הזה |
בודק אם היתרון של EFT נשאר לאחר שינויים בפיזור RC הפנימי המשוער. |
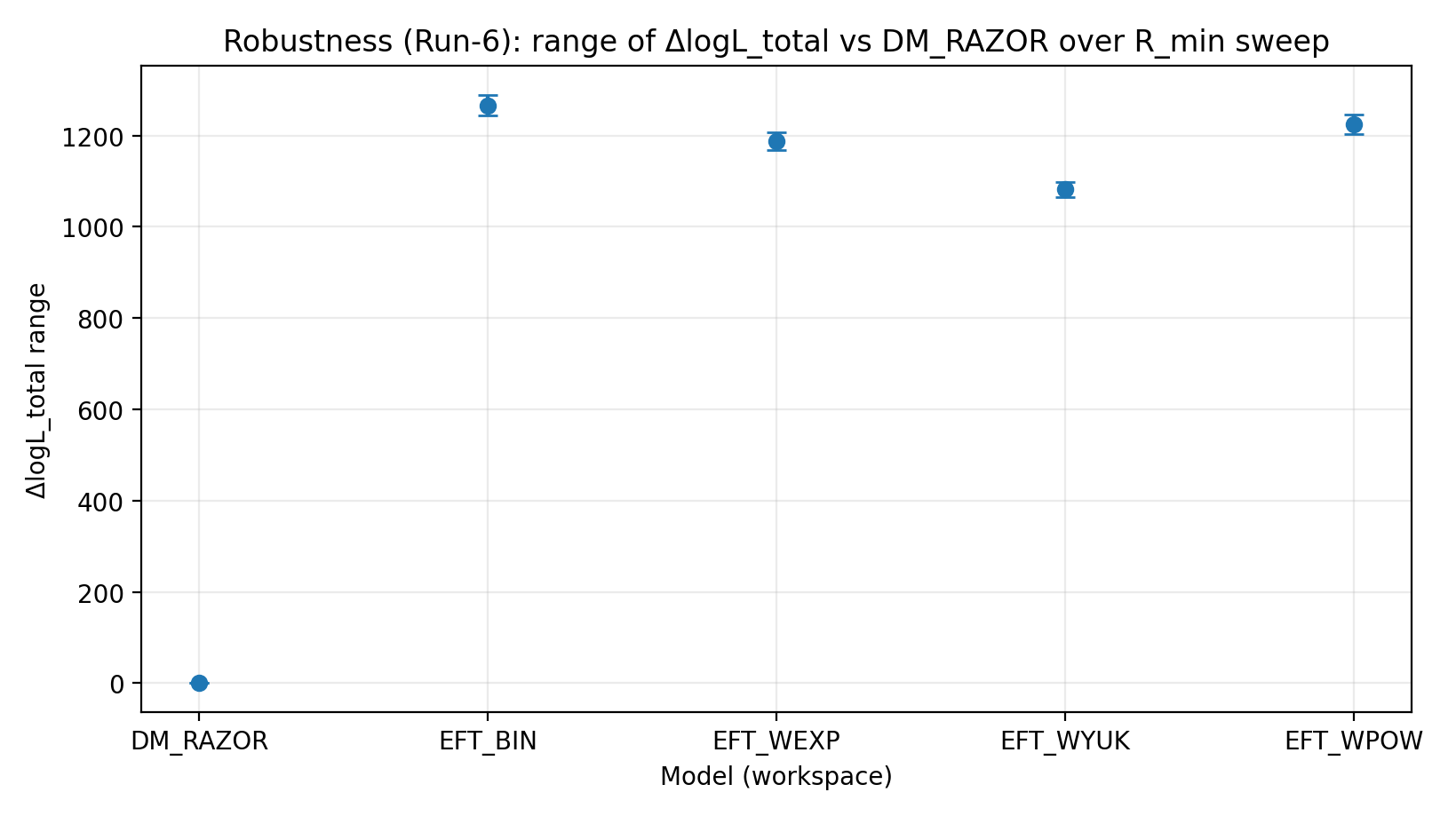
איור R3 | טווח ΔlogL_total תחת סריקת R_min (גדול יותר טוב יותר).
איך לקרוא את האיור הזה |
בודק אם יתרון EFT נשאר יציב לאחר קיטום אזורים מרכזיים מורכבים. |
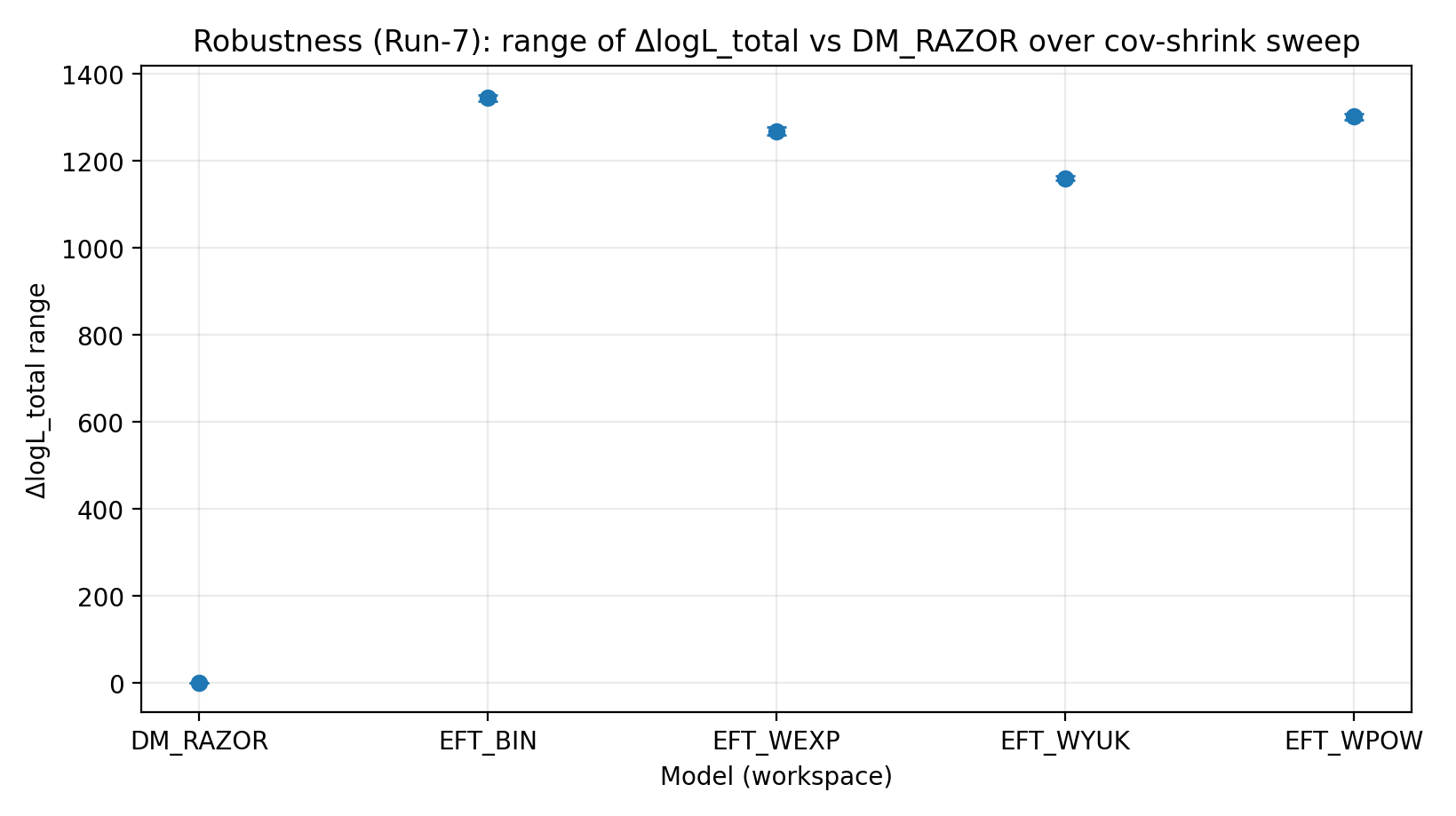
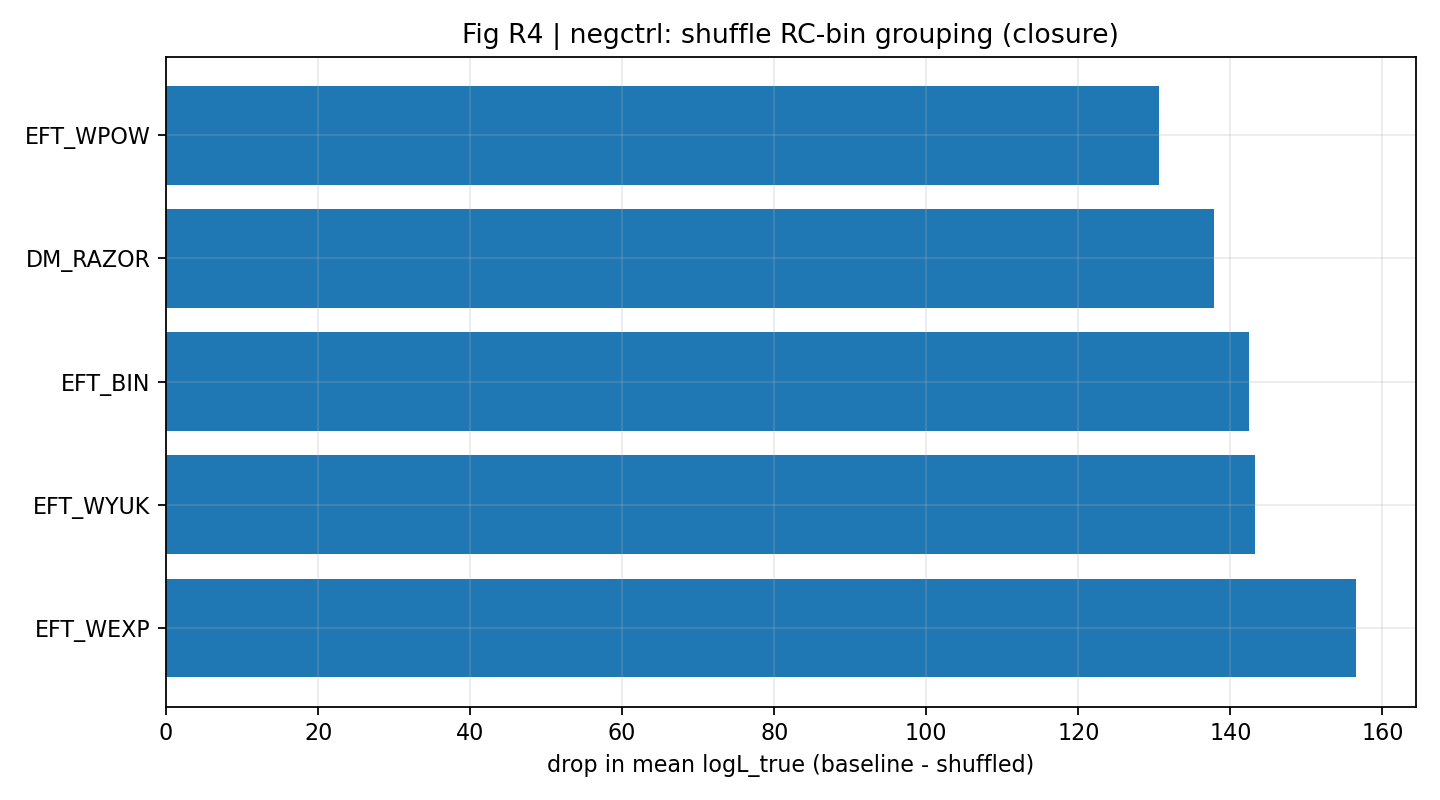
איור R4 | טווח ΔlogL_total תחת סריקת cov-shrink (גדול יותר טוב יותר).
איך לקרוא את האיור הזה |
בודק אם הדירוג רגיש לשינויים בטיפול בקווריאנציה של עידוש חלש. |
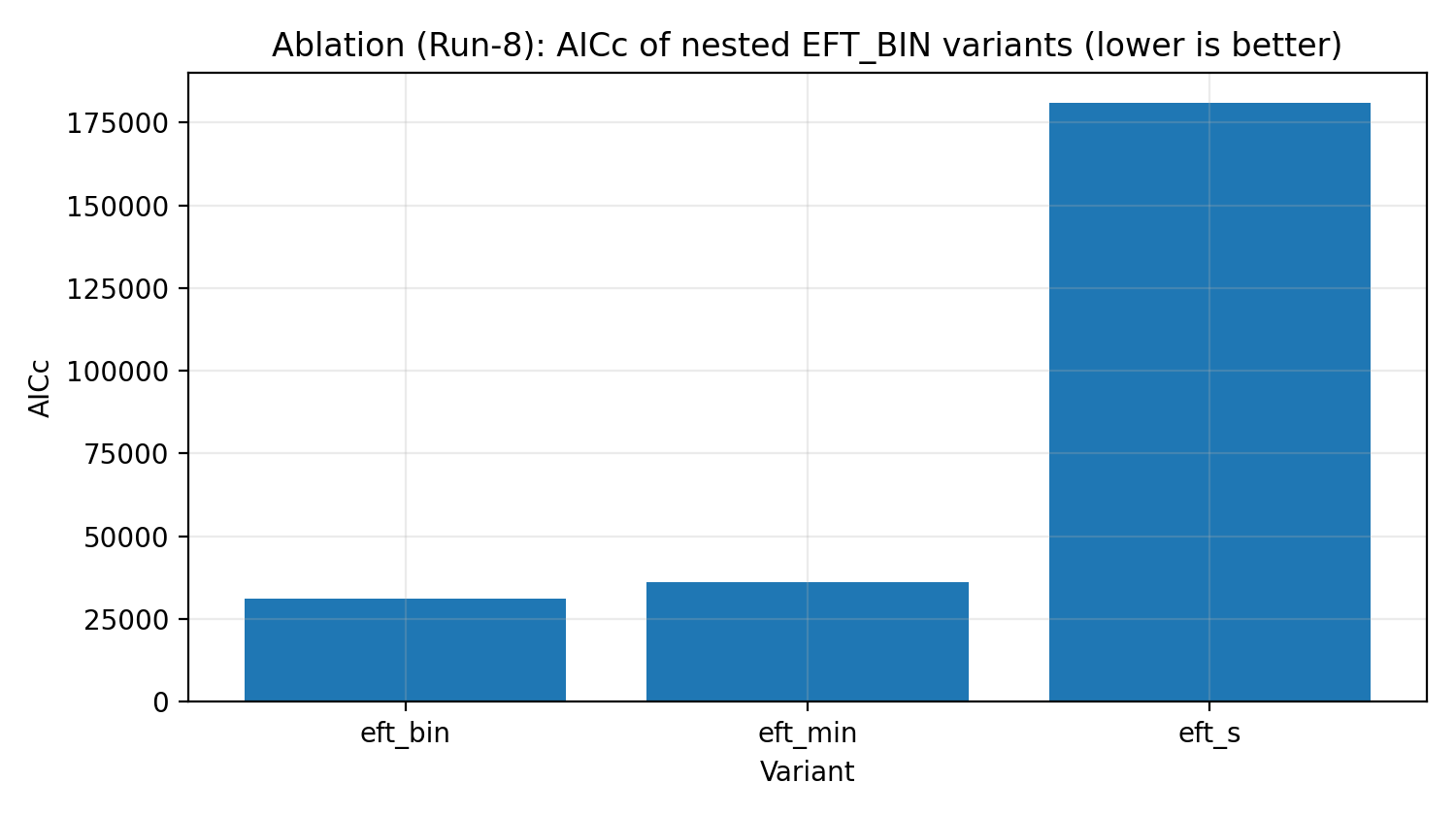
איור R5 | סולם אבלציה של EFT_BIN (AICc, קטן יותר טוב יותר).
איך לקרוא את האיור הזה |
בודק אם EFT_BIN המלא נחוץ להסבר הנתונים, ולא רק מוסיף פרמטרים מיותרים. |
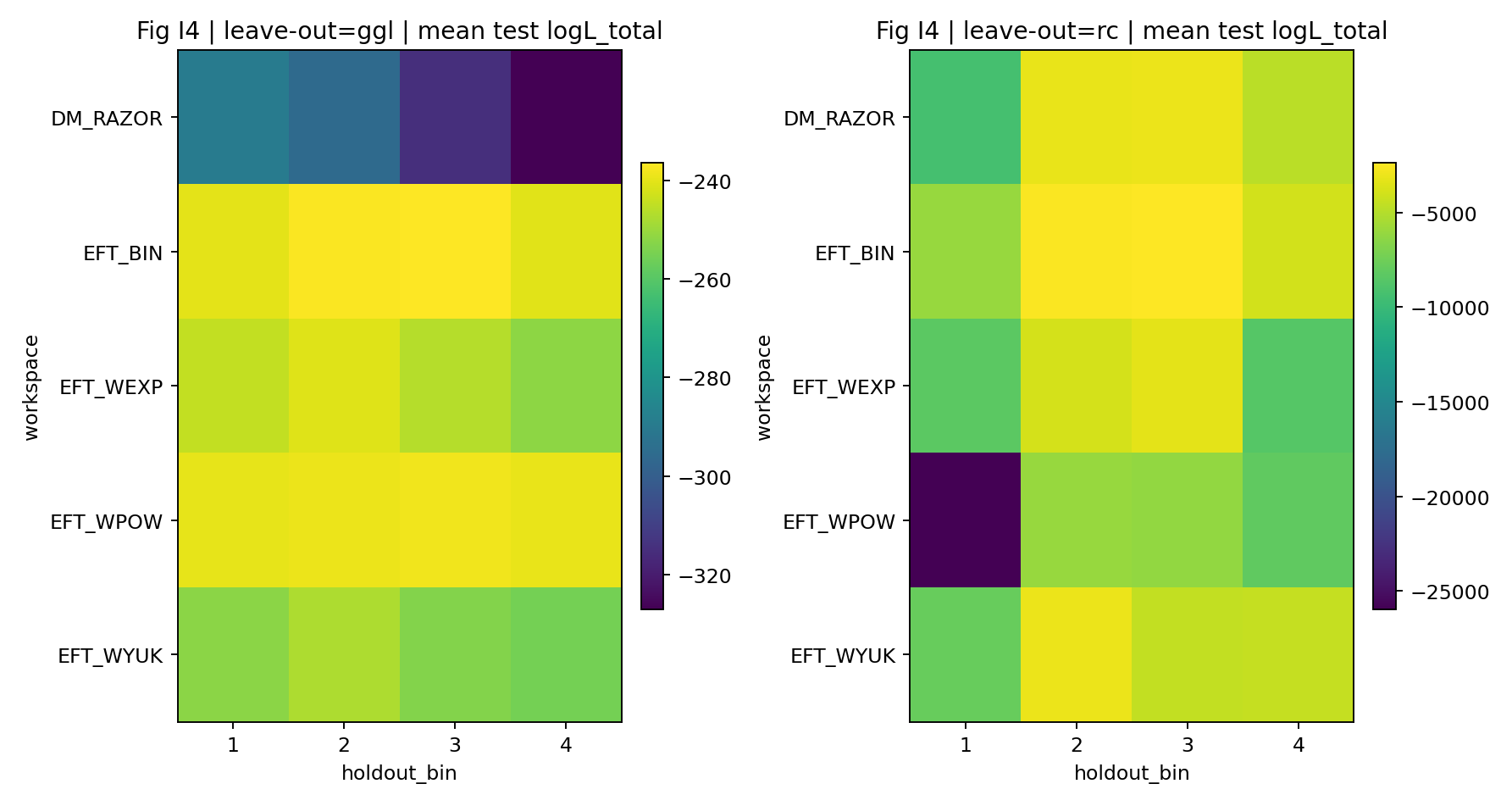
איור R6 | LOO: התפלגות לוג־הסבירות עבור תאים שהוחזקו בחוץ.
איך לקרוא את האיור הזה |
בודק אם למודל עדיין יש ביצועי חיזוי על תאי GGL שלא נראו. |
איור R7 | בקרה שלילית: מיפוי מעורבל גורם לירידה ברורה ב־mean logL_true של הסגירה.
איך לקרוא את האיור הזה |
מראה עוד, מנקודת המבט של mean logL_true, שהסגירה תלויה במיפוי הנכון בין הנתונים. |
9 | P1A: מדוע ״כמה מודלי DM בנספח״ הוא תיקון מרכזי
סעיף זה אינו שואל: ״האם EFT ניצחה רק קו בסיס DM_RAZOR מינימלי אחד?״ הוא שואל אם מסקנות מבחן הסגירה וההתאמה המשותפת משתנות כאשר קו הבסיס של DM מחוזק בתוך פנקס פרמטרים בממד נמוך, ניתן לשחזור ומתועד בבירור (P1A). במילים אחרות, P1A מבקש לצמצם את ההתנגדות ש״פשוט נבחר קו בסיס DM חלש מדי״, ולהעביר את הדיון לשאלה אם התנהגות הסגירה עדיין שונה תחת מערכת של שיפורי DM ניתנים לביקורת.
P1A אינו נועד למצות כל מידול אפשרי של הילות LambdaCDM, וגם אינו הופך את צד DM למתאים רב־ממדי שאינו ניתן לביקורת. הוא בוחר שיפורים בממד נמוך, בני שחזור ובעלי פנקס פרמטרים ברור: פיזור ריכוז, כיווץ אדיאבטי, ליבת משוב, prior היררכי לפיזור c–M, proxy ליבה בפרמטר אחד, nuisance של כיול shear בעידוש חלש, וקו הבסיס המשולב DM_STD.
הקריאה הראשית של P1A |
מבין שלושת ענפי ה־legacy, רק feedback/core מייצר עלייה נטו קטנה בחוזק הסגירה; SCAT ו־AC אינם מייצרים רווחי סגירה נטו. |
ל־DM_HIER_CMSCAT, ל־DM_RAZOR_M ול־DM_CORE1P יש השפעה קטנה מאוד על חוזק הסגירה או שאין בהם שיפור נטו משמעותי. |
DM_STD יכול לשפר משמעותית את logL המשותף, אך חוזק הסגירה שלו יורד, מה שמרמז שהוא משפר בעיקר את גמישות ההתאמה המשותפת ולא את כוח חיזוי ההעברה RC→GGL. |
EFT_BIN עדיין שומרת על חוזק סגירה גבוה יותר ועל יתרון בהתאמה המשותפת בטבלה B1 של P1A; לכן אין לצמצם את הטענה המרכזית של P1 ל״היא ניצחה רק את DM_RAZOR המינימלי״. |
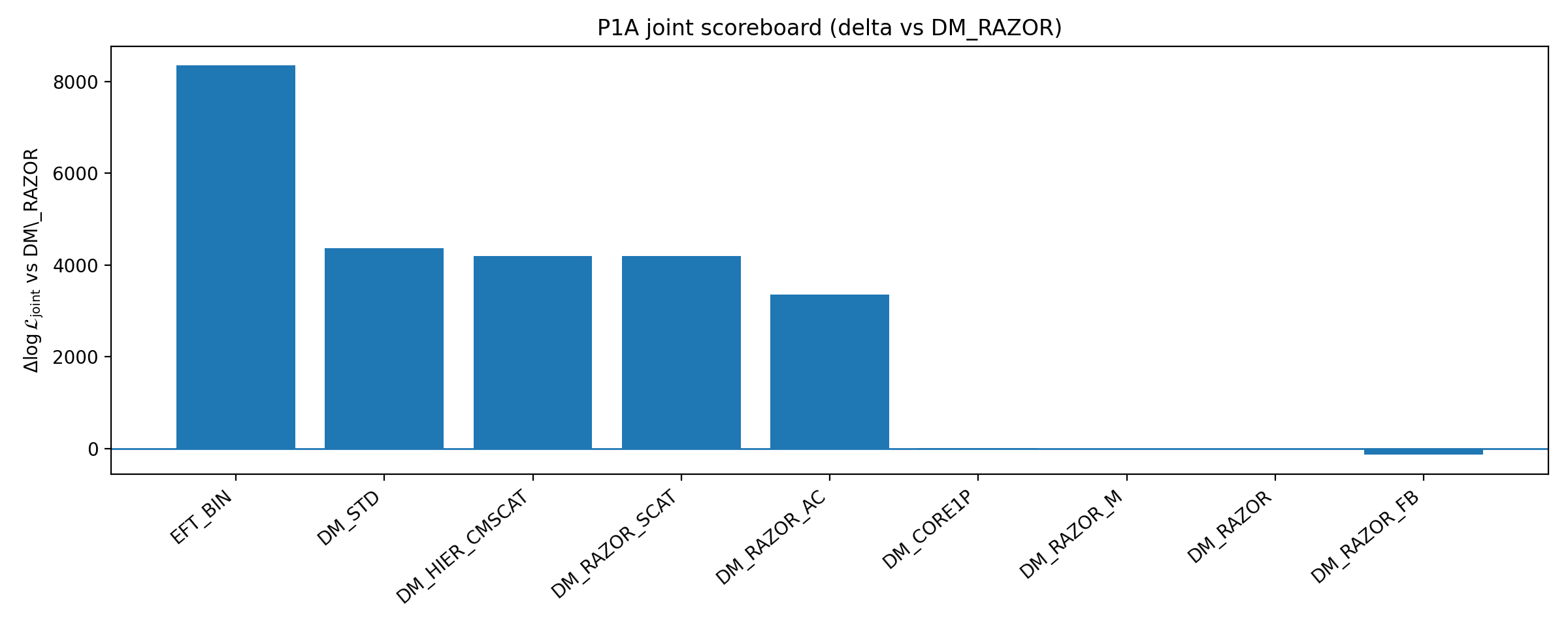
איור B1 | לוח התוצאות של P1A: סגירה ו־ΔlogL משותף ביחס לקו הבסיס (גדול יותר טוב יותר).
איך לקרוא את האיור הזה |
האיור הזה מציג את ביצועיהם של כמה ענפי שיפור DM ביחס לקו הבסיס. |
משמעותו אינה ״כל DM נשלל״, אלא זו: בתוך שיפורי DM בממד נמוך וניתנים לביקורת שנבחרו על ידי P1A, חיזוק DM אינו מסיר את יתרון הסגירה של EFT_BIN. |
10 | למה ניסוי P1 חשוב
10.1 חשיבות מתודולוגית: הצבת ״סגירה בין ערוצי מדידה״ מעל ״התאמה לערוץ יחיד״
תיאוריה בקנה מידה גלקטי יכולה בקלות להיתקע בשאלה אם מודל מתאים לקבוצה מסוימת של עקומות סיבוב. P1 מעלה את השאלה רמה אחת: האם פרמטרים שנלמדו מ־RC יכולים לחזות עידוש חלש בלי כוונון מחדש ל־GGL? כך P1 הופך מ״תחרות התאמה״ ל״מבחן חיזוי־העברה״.
10.2 חשיבות השקיפות: התייחסות לשרשרת השחזור כחלק מן התוצאה
תרומה חשובה אחת של P1 היא שהוא משחרר יחד את הנתונים, הטבלאות והאיורים, תוויות הריצות, הבקרות השליליות, חבילת השחזור ושרשרת הביקורת. הדבר חשוב גם לתומכים וגם למבקרים: הדיון יכול לחזור לאותם נתונים ציבוריים, אותו מיפוי, אותם סקריפטים ואותם מדדים, במקום להשוות סיסמאות.
10.3 חשיבות פיזיקלית: מבחן מאמץ חזק לכיווני ״כבידה שאינה חומר אפל״
בכיווני כבידה שאינם חומר אפל, מודלים רבים יכולים להסביר חלק מעקומות הסיבוב או מן RAR. המשימה הקשה יותר היא לעבור גם קריאות עידוש חלש ולהראות, תחת בקרות שליליות, שהאות תלוי במיפוי הנכון. P1 חשוב משום שהוא מכניס את תגובת הכבידה הממוצעת של EFT לפרוטוקול הדומה לבחינה חיצונית: RC הוא מגרש האימון, GGL הוא שדה ההעברה, ו־shuffle הוא שדה האנטי־רמאות.
10.4 האם זהו ניסוי חשוב לתחום ״כבידה שאינה חומר אפל״?
בניסוח זהיר: אם עיבוד הנתונים של P1, חבילת השחזור ופרוטוקול הסגירה יעמדו בביקורת חיצונית, ניתן לראות בו ניסוי סגירה RC+GGL שראוי להתייחסות רצינית בכיווני כבידה שאינה חומר אפל / כבידה מותאמת. חשיבותו אינה בסיסמה ״החומר האפל הופרך״, אלא בכך שהוא מציע קריטריון בין ערוצי מדידה שניתן לשחזר, לאתגר ולהרחיב.
האם קיימות כבר מסגרות חיזוי־סגירה RC+GGL באותה רמה? |
יש מסגרות ומסורות תצפית רלוונטיות: MOND/RAR מארגן היטב תופעות רבות של עקומות סיבוב; עבודת RAR בעידוש חלש KiDS-1000 השוותה גם את MOND, כבידה מתהווה של Verlinde ומודלי LambdaCDM; LambdaCDM יכול גם להסביר כמה תופעות עידוש חלש/דינמיות באמצעות קשרי גלקסיה–הילה, הילות גז ומידול משוב. |
אבל הטענה המדויקת של P1 אינה ש״אין מסגרת אחרת בעולם שיכולה להסביר RC+GGL״. אלא שתחת הפרוטוקול הציבורי של P1 עצמו—מיפוי קבוע, סגירת RC בלבד→GGL, בקרות שליליות של ערבוב, פנקס פרמטרים ומבחני מאמץ מרובי־DM של P1A—EFT מדווחת על ביצועי סגירה חזקים יותר. |
במילים אחרות, החלק ב־P1 שהכי ראוי לבדיקה חיצונית הוא פרוטוקול ההשוואה הקונקרטי והבר־שחזור שלו. צעד הבא ראוי מאוד הוא לבדוק אם MOND/RAR, LambdaCDM/HOD, סימולציות הידרודינמיות או מסגרות אחרות של כבידה מותאמת יכולות להגיע לאותם ציוני סגירה או גבוהים יותר תחת אותו פרוטוקול. |
11 | מה P1 יכול להסיק, ומה הוא אינו יכול להסיק?
טבלה 3 | גבולות המסקנות של P1
תחת נתוני RC+GGL של P1, המיפוי הקבוע ופרוטוקול ההשוואה הראשי, למשפחת EFT יש ציוני התאמה משותפת וחוזק סגירה גבוהים יותר מאשר DM_RAZOR המינימלי. | ניתן להסיק |
בתוך טווח שיפורי DM בממד נמוך וניתן לביקורת של P1A, כמה שיפורי DM אינם מבטלים את יתרון הסגירה של EFT_BIN. | ניתן להסיק |
בקרת הערבוב השלילית מראה שאות הסגירה תלוי במיפוי הנכון בין הנתונים ואינו מתקבל תחת מיפויים שרירותיים. | ניתן להסיק |
אי אפשר לומר ש־P1 הפך על פיהם את כל מודלי החומר האפל. P1A עדיין אינו ממצה אי־כדוריות, תלות סביבתית, קשרי גלקסיה–הילה מורכבים, משוב רב־ממדי או סימולציות קוסמולוגיות מלאות. | לא ניתן להסיק |
אי אפשר לומר שמסגרת EFT השלמה הוכחה מעקרונות ראשונים. P1 בוחן רק את השכבה הפנומנולוגית של תגובת כבידה ממוצעת. | לא ניתן להסיק |
אי אפשר לומר שכל השיטתיות נשללה. P1 מספק ראיות חסינות רק בתוך מבחני המאמץ והיקף הביקורת הרשומים. | לא ניתן להסיק |
12 | שאלות נפוצות מקוראים כלליים
שאלה 1: האם פירוש הדבר הוא ש״החומר האפל אינו קיים״?
לא. יש להגביל את מסקנות P1 לנתונים, לפרוטוקול ולמודלי ההשוואה המשמשים כאן. P1A חורג מעבר ל־DM_RAZOR המינימלי, אך עדיין אינו מייצג את כל מודלי החומר האפל האפשריים.
שאלה 2: האם פירוש הדבר הוא ש״EFT הוכחה״?
גם לא. P1 בוחן את EFT כפרמטריזציה של תגובת כבידה ממוצעת ומראה ביצועים חזקים יותר בסגירת RC→GGL; המנגנון המיקרוסקופי והתיאוריה השלמה אינם מסקנת P1.
שאלה 3: למה לא לדווח ישירות ערך מובהקות ב־σ?
P1 משתמש בציוני סבירות מאוחדים, בקריטריוני מידע ובהפרשי סגירה. ΔlogL הוא יתרון יחסי תחת אותו כלל ניקוד; הוא אינו שקול לערך σ יחיד.
שאלה 4: למה לערבל RC-bin→GGL-bin?
זו בקרה שלילית. אות אמיתי בין ערוצי מדידה אמור להיות תלוי במיפוי הנכון; אם הוא נותר חזק באותה מידה אחרי ערבוב, הדבר היה מרמז במקום זאת על הטיית יישום אפשרית או על אות סטטיסטי כוזב.
שאלה 5: מה P1 צריך לעשות בהמשך?
להרחיב את אותו פרוטוקול ליותר נתונים, יותר השוואות DM, שיטתיות מורכבת יותר ועוד מסגרות של כבידה מותאמת—במיוחד בדרכים שמאפשרות לצוותים חיצוניים לבדוק מחדש תחת אותו מדד סגירה.
13 | מילון מונחים קצר
טבלה 4 | מילון מונחים קצר
הסבר במשפט אחד | מונח |
יחס רדיוס–מהירות סיבוב בדיסקת גלקסיה, המשמש להסקת כבידה אפקטיבית בתוך הדיסקה. | עקומת סיבוב (RC) |
מדד להתפלגות הכבידה/המסה הממוצעת סביב גלקסיות קדמיות באמצעות העיוות הסטטיסטי של צורות גלקסיות הרקע. | עידוש חלש (GGL) |
משתמש ב־posterior של RC כדי לחזות GGL, ואז משווה אותו לבקרה השלילית הנוצרת ממיפוי מעורבל. | מבחן סגירה |
שוברת בכוונה מבנה מרכזי כדי לראות אם האות נעלם; משמשת לשלילת אותות כוזבים. | בקרה שלילית |
פרופיל צפיפות של הילת חומר אפל הנמצא בשימוש נפוץ במודלי חומר אפל קר. | הילת NFW |
היחס בין ריכוז הילת חומר אפל c לבין מסה M; השאלה אם מותר פיזור משפיעה על גמישות המודל. | יחס c–M |
ענף מבחן המאמץ DM הסטנדרטי ב־P1A, המשלב כמה שיפורי DM בממד נמוך ואיבר nuisance של עידוש. | DM_STD |
הפרש הלוג־סבירות בין שני מודלים תחת אותו כלל ניקוד; ערך חיובי פירושו שהראשון טוב יותר. | ΔlogL |
תיאור מטריציוני של מתאמים בין נקודות נתונים; נתוני עידוש חלש דורשים בדרך כלל את הקווריאנציה המלאה. | קווריאנציה |
14 | מסלול קריאה מוצע ונקודות כניסה לציטוט
1. קראו תחילה את סעיפים 0–2 במדריך זה כדי לבסס את שאלת P1 ואת תפקידה המרוסן במכוון של EFT ב־P1.
2. לאחר מכן קראו את איור S3, איור S4 וטבלאות S1a/S1b כדי להבין את חוזק הסגירה, ההתאמה המשותפת והבקרות השליליות.
3. אם אתם חוששים ש״קו הבסיס של DM חלש מדי״, עברו ישירות לסעיף 9 ולטבלה B1 / איור B1.
4. לאימות טכני, חזרו לדוח הטכני P1 v1.1, לנספח הטבלאות והאיורים, ול־full_fit_runpack.
נקודות כניסה ראשיות לארכיונים |
דוח טכני של P1 (רמת release, Concept DOI): 10.5281/zenodo.18526334 |
חבילת שחזור מלאה של P1 (Concept DOI): 10.5281/zenodo.18526286 |
בסיס הידע המובנה של EFT (אופציונלי, Concept DOI): 10.5281/zenodo.18853200 |
הערת רישיון: הדוח הטכני משתמש ב־CC BY-NC-ND 4.0; חבילת השחזור המלאה משתמשת ב־CC BY 4.0 (יש להתייחס לדוח הטכני ולארכיוני Zenodo כמקורות הסמכותיים). |
15 | מקורות ורקע חיצוני
McGaugh, S. S., Lelli, F., & Schombert, J. M. (2016). The Radial Acceleration Relation in Rotationally Supported Galaxies. Physical Review Letters, 117, 201101. DOI: 10.1103/PhysRevLett.117.201101.
Famaey, B., & McGaugh, S. S. (2012). Modified Newtonian Dynamics (MOND): Observational Phenomenology and Relativistic Extensions. Living Reviews in Relativity, 15, 10. DOI: 10.12942/lrr-2012-10.
Brouwer, M. M., Oman, K. A., Valentijn, E. A., et al. (2021). The weak lensing radial acceleration relation: Constraining modified gravity and cold dark matter theories with KiDS-1000. Astronomy & Astrophysics, 650, A113. DOI: 10.1051/0004-6361/202040108.
Mistele, T., McGaugh, S., Lelli, F., Schombert, J., & Li, P. (2024). Indefinitely Flat Circular Velocities and the Baryonic Tully-Fisher Relation from Weak Lensing. The Astrophysical Journal Letters, 969, L3 / arXiv:2406.09685.
Bullock, J. S., & Boylan-Kolchin, M. (2017). Small-Scale Challenges to the LambdaCDM Paradigm. Annual Review of Astronomy and Astrophysics, 55, 343–387. DOI: 10.1146/annurev-astro-091916-055313.
Lelli, F., McGaugh, S. S., & Schombert, J. M. (2016). SPARC: Mass Models for 175 Disk Galaxies with Spitzer Photometry and Accurate Rotation Curves. The Astronomical Journal, 152, 157. DOI: 10.3847/0004-6256/152/6/157.
Navarro, J. F., Frenk, C. S., & White, S. D. M. (1997). A Universal Density Profile from Hierarchical Clustering. Astrophysical Journal, 490, 493.
Dutton, A. A., & Macciò, A. V. (2014). Cold dark matter haloes in the Planck era: evolution of structural parameters for NFW haloes. Monthly Notices of the Royal Astronomical Society, 441, 3359–3374.